書籍版「建設ITガイド」に掲載した特集記事のバックナンバーです。
土木におけるAI活用の現状と将来
2024.07.17第3次AIブーム
現在は、1956年に開催されたダートマス会議で「人工知能(AI)」という言葉が登場して以来3回目のAIブームと言われています。
第1次ブームでは、それまでは人間しかできないと考えられていた探索や推論が可能となり、コンピューターが数学の定理証明や簡単なゲームのような特定の問題に対して、答えを出せることが分かりました。
当時としては画期的なことでしたが、複雑な現実の問題を解くまでには至りませんでした。
第2次ブームでは、知識をルールの形で表してコンピューターに推論させる「エキスパートシステム」が登場し、より現実的な問題が解けるようになります。
知識を表現したルール自体は人間が作る必要がありますから、一般的な問題を解こうとすると膨大なルールが必要になります。
そこで、専門性の高い比較的限られた問題への適用が進められました。
AIの別の流れとして、脳内の神経細胞をコンピューター上で模擬した人工ニューロンを組み合わせて、人間のような思考を実現しようとする「ニューラルネットワーク」の考え方があります。
第3次ブームでは、コンピューターの進歩や、インターネットなどによって大量のデータが得やすくなってきたことを背景に、多層化したニューラルネットワークを用いる「深層学習」が発展します(図-1)。
2012年の国際画像認識コンペで、ヒントンのグループが深層学習を用いて画期的な精度の向上を実現(文献1)したことを契機に急速に進展しました。
同じ年に、大規模なニューラルネットワークに多数の画像を読み込ませることで、教師データを与えなくても「猫」を検出する人工ニューロンが現れたことが発表されたこともあり(文献2)、社会的な関心も高まりました。
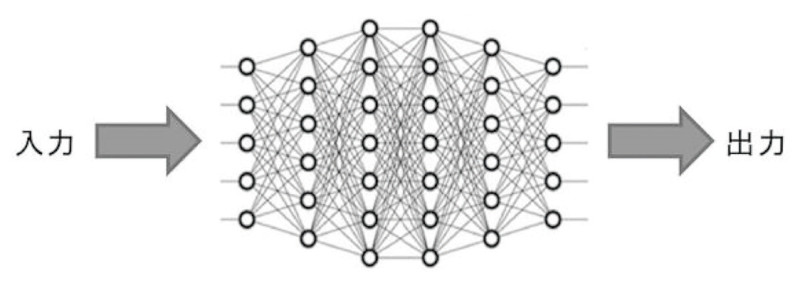
図-1 深層学習に使われる多層化したニューラルネットワーク
2016年にはAIがトッププロの囲碁棋士を破ったことが話題になりました。
それには「強化学習」という考え方が用いられています。
囲碁のようなゲームでは明確な勝ち負けがありますから、人間が教えなくても、 AIが自分自身と膨大な対局をすることで勝ちにつながる手筋を学習し、自ら強化していくことができます。
さらに、2022年には、画像や対話を生成するAIが登場し、今なお大きな話題となっています。
その仕組みは、あらかじめ膨大な文章をトランスフォーマー(Transformer)と呼ばれるAIに読み込ませた「大規模言語モデル(LLM:Large Language Model)」です。
大規模言語モデルは、規模を大きくすればするほど精度が向上していくことが知られており、ますます規模を拡大しています。
このように、第3次AIブームでは、新しい技術が次々と生まれ、実社会での応用が進んでいます。
もはやブームとは言えないほどAIが日常的なものとなっていると言ってよいでしょう。
土木における応用も広がっています。
画像認識
第3次AIブームの端緒となったのが「畳み込みニューラルネットワーク(CNN:Convolutional Neural Networks)」と呼ばれる深層学習の方法を用いた画像認識です。
CNNの原型は福島邦彦氏によるネオコグニトロンであることは広く知られています(文献3)。
土木の実務では、現場や図面などを目で見て判断する業務が随所にありますから、画像認識AIの活躍の場も大きいと考えられます。
典型的なAIの応用として、点検の際の画像から、ひび割れを見つける問題があります。
一口にひび割れを見つけると言っても、図-2に整理したように、いくつかのレベルが考えられます(文献4)。
左図は、ひび割れの含まれる画像と含まれない画像を「分類」することで、ひび割れのある画像を検出するものです。
中央の図は、ひび割れのある領域を「バウンディングボックス」で囲んで検出しています。
右図は、ひび割れの箇所を画素レベルで分類して検出しているもので、「セマンティックセグメンテーション」と呼ばれます。
画像の中のひび割れの有無が分かればいい場合もあれば、ひび割れの長さや幅まで知りたい場合もあるでしょう。
画像認識の目的や用途によって異なる方法が用いられます。

図-2 分類・バウンディングボックス・セグメンテーションと教師データ作成コスト(文献4)
この図の下に、AIに学習させるための教師画像を作成するコストのイメージが示されています。
左の画像分類では、画像ごとにラベルを付ける「アノテーション」をすればよいのですが、右のひび割れの画素を検出する場合は画素ごとにアノテーションする必要がありますから、手間が大きく異なります。
中央のバウンディングボックスはその中間くらいでしょう。
画像認識のAIを作るに当たっては、ニーズや用途とコストのバランスを考えて最適な方法を考えることになります(図-2)。
画像による物体検出は、建設現場でも有効です。
図-3は、移動中のクレーンのフックに吊り下げた重量計測用のクレーンスケールと鉄筋を検出した例です(文献5)。
安全管理を考えると、クレーンに吊られた重量物などはリアルタイムで検出することが望まれるので、ここでは「YOLO」と呼ばれる高速な手法が用いられています。
YOLOは「“You only look once(”一目見るだけでいい)」の頭文字で、ラップの YOLO「“You only live once”(人生一度きり)」の語呂合わせになっています。
AIの手法の名前には特長を端的に表したしゃれたものも多いです。
物体検出は、交通の計測や、廃棄物の検出などへの応用も進められています。

図-3 建設現場での物体検出(文献5)
打音検査・異常検出
AIで分類できるのは画像だけではありません。
コンクリートの健全性を調べるために、打音検査が用いられますが、コンクリートを打撃する際の音響データを健全部と異常部に分類するのにもAIが適用可能です。
一例として、文献6では、図-4-1のように実際の構造物で録音した打音のデータに対して、「オートエンコーダ(自己符号化器)」(図-4-2)と呼ばれる深層学習を適用しています。
オートエンコーダは、入力と出力に同じデータ(この場合は打音の波形)を用いて学習することで、入力と同じ出力を再現する仕組みです。
正常音でオートエンコーダを学習させると、異常音を入力した場合にはオートエンコーダでは再現されないことが分かりました。
その性質を応用することで、打音の判別に成功しています。
オートエンコーダでは、人間がアノテーションして教師データを作る必要がないのも一つのメリットです。

図-4-1 打音の録音状況(文献6)
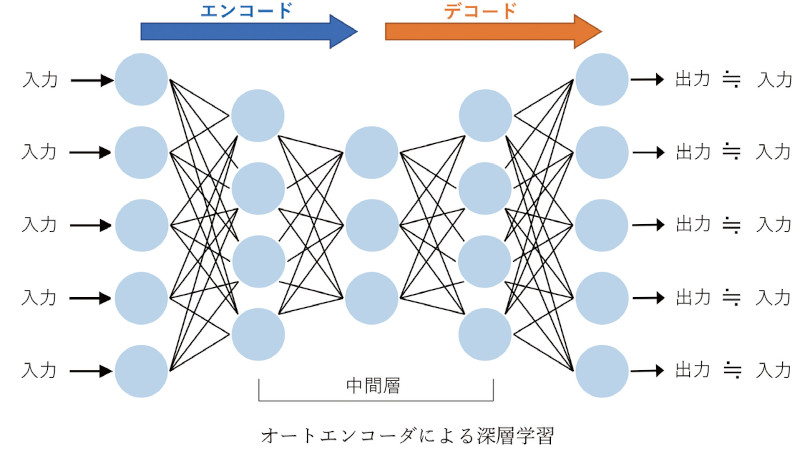
図-4-2 オートエンコーダによる深層学習(文献6)
ほとんどの構造物は健全ですから、異常のデータというものはそもそも少ないものです。
健全データと異常データをそのまま学習して、異常を検知しようとすると、異常データの方が圧倒的に少ないため、単に当てずっぽうで「健全」と判定するだけでも、高い正解率となってしまうことがあります。
そこで、この打音の事例のように健全を再現するAIによる予測値と実測値のずれから異常を検知したり、図-5のように多い方の健全データを減らすアンダーサンプリング、少ない方の異常データを増やすオーバーサンプリングなど、「サンプルバランシング」の手法などを用いたりすることもあります。
その他、シミュレーションでデータを生成したり、物理的知見を反映するしたりするなど、いろいろな解決法の研究が進められています(文献7)。

図-5 異常時データなどの不均衡なデータの取り扱い(文献7)
このように不均衡があるデータの場合にAIの性能を評価するには、単に全体的な精度のみならず、異常の見逃しにつながる未検出や、誤検出による空振りにも注意する必要があります。
AIの評価では、未検出に関する指標である「適合率(precision)」や、誤検出に関する指標である「再現率(recall)」が用いられるのが一般的です(文献8)。
AIはどこを見ているのか
AIはブラックボックスと言われますが、ある程度は、AIの根拠を示すことができます。
AIの推論結果を人間が解釈可能な形で出力する技術は「説明可能AI(XAI:eXplainable AI)」と呼ばれ、図-6のようなヒートマップもその一つです。

図-6 鋼主桁の腐食とAIの着目領域のヒートマップ(文献9)
図-6は橋の点検時に撮影された写真から、健全あるいは損傷が軽微なものと、損傷が大きく補修などの検討が必要なものに分類するAI(文献9)で分類された、損傷が大きな場合の例です。
右のヒートマップは、画素ごとにAIの判定に寄与した度合いを表しています。
腐食が進んでいる主桁補剛材下端付近が赤色になっており寄与が大きくなっています。
点検写真を分類するAIでも、人間と同様の着目箇所の情報を使って判定していることが分かります。
大規模言語モデル
ヒートマップのようにAIが着目している領域の情報を利用するのが、「アテンション(注意機構、Attention)」と呼ばれる方法です。
アテンションを中心に据えたAIが、近年提案されたトランスフォーマーで、ChatGPTなどの大規模言語モデルや現在のAIの基本になっています(文献10)。
トランスフォーマーを提案した論文は「Attention Is All You Need」というタイトルで、アテンションの重要性が強調されています。
ビートルズの「All You Need Is Love 」を思い起こさせます(文献11)。
言語のアテンションは、文章の前後関係や翻訳や会話などの対となる文章から、単語間の関連度や注目度を抽出するものです。
文献12では、トランスフォーマーの一種であるBERTという手法を、SNSの投稿に適用して、災害に関係のあるものを抽出しています。
図-7は、災害に関係あると分類された投稿について、各単語のアテンションを、関連性が強いほど赤色が濃くなるように可視化したものです。
時間や住宅が水に浸かっている様子など、人間にとって重要な単語に注目していることが分かります。

図-7 災害に関係があると分類された投稿とアテンション(文献12)
大規模言語モデルでは、膨大な文章のパターンを事前に学習することで、人間に近い自然な受け答えが実現されています。
さらに、「プロンプト」と呼ばれる問いかけの方法を工夫したり、追加的な学習を行うことでモデルを微調整する「ファインチューニング(fine tuning )」を行ったりすることで、専門的な問題に対する回答を生成する試みも進められています(文献13)。
また、図-8は、別のユースケースとして、大規模言語モデルによってNETISの新技術を分類した例で(文献13)、点が近いほど類似性が高くなっています。
赤の工法と、青の製品や紫の材料に関する技術は入り乱れて表示されていて、関連性が強いことが分かります。
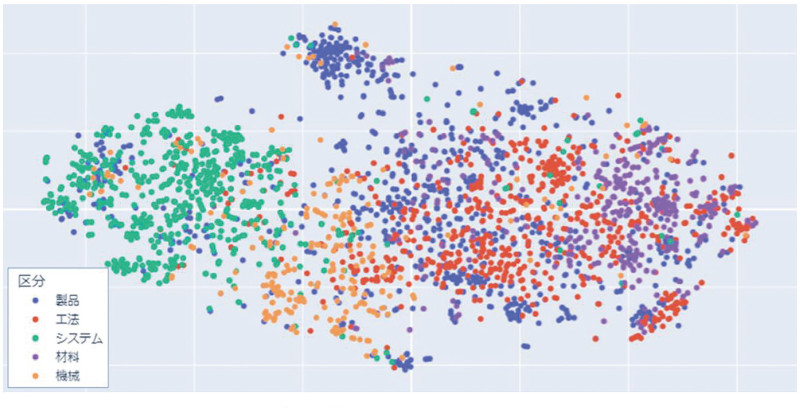
図-8 大規模言語モデルを用いた新技術の分類例(文献13)
デジタルトランスフォーメーションに向けて
トランスフォーマーは、言語のみならず画像にも適用可能です。
画像の場合でも、専門分野の画像を追加してファインチューニングをすることができます。
インフラ点検の損傷画像などデータ数が限られる場合にも有望なアプローチであると考えられます。
図-9は、点検画像と、その画像に対応するアテンションを表示したアテンションマップの例です。
剝落やひび割れなど、損傷に関連する領域が強調されるようにアテンションが高くなっています(文献14)。

大規模言語モデルのベースとなるトランスフォーマーは、言語のみならず、画像などの多様なデータに適用できます。
言語、画像、センサーデータなどを組み合わせたマルチモーダルなデータへの拡張も可能です。
例えば、GPT-4Vでは、画像を言語で説明するなどの機能が大幅に強化されています(文献15)。
土木の実務では、特に、画像と言語からなるデータを用いる場面も多く、橋梁点検調書作成の省力化(文献16)に向けた研究や、土砂災害の画像から危険度を判定する研究(文献17)などが行われています。
文献18では、図-10のように点検時の変状画像に対する所見の生成を試みています。
技術者の所見を完全に再現するには至っていませんが、赤字の部分のポイントについては整合していることが分かります。

図-10 技術者とAIによる所見の比較(文献18)
大規模言語モデルの土木への応用は始まったばかりですが、画像の利活用と合わせて、実際のさまざまな業務の場面で、直接、仕事に取り入れることのできるユースケースが考えられています。
AIによるデジタルトランスフォーメーションの一層の進展が期待されます。
文献
(1)Olga Russakovsky,Jia Deng,Hao Su,Jonathan Krause,Sanjeev Satheesh,Sean Ma,Zhiheng Huang,Andrej Karpathy,Aditya Khosla,Michael Bernstein,Alexander C.Berg,Li Fei-Fei:Image Net Large Scale Visual Recognition Challenge
https://doi.org/10.48550/arXiv.1409.0575
(2)Jeff Dean,Andrew Ng:Using large-scale brain simulations for machinelearning and A.I.
https://blog.google/technology/ai/using-large-scale-brain-simulations-for/
(3)福島 邦彦:深層畳み込み神経回路ネオコグニトロン,認知科学,2022年29巻1号p.14-23.https://doi.org/10.11225/cs.2021.061
(4)泉 翔太,全 邦釘:Attention機構を用いたDeep Learningモデルによるひび割れ自動検出,AI・データサイエンス論文集,2021年2巻J2号p.545-555.https://doi.org/10.11532/jsceiii.2.J2_545
(5)楠本 雅博,Ayiguli AINI,全 邦釘:建設現場における人工知能の活用事例,AI・データサイエンス論文集,2020年1巻J1号
p.301-306.https://doi.org/10.11532/jsceiii.1.J1_301
(6)江本 久雄,馬場 那仰,浅野 寛元,長瀬 大和:AI手法による打音検査の浮き判定の検討,AI・データサイエンス論文集,2020年1巻J1号p.514-521.https://doi.org/10.11532/jsceiii.1.J1_514
(7)宮本 崇,浅川 匡,久保 久彦,野村 泰稔,宮森 保紀:防災応用の観点からの機械学習の研究動向,AI・データサイエンス論文集,2020年1巻J1号p.242-251.https://doi.org/10.11532/jsceiii.1.J1_242
(8)“土木×AI”で起きる建設現場のパラダイムシフト【第13回】土砂崩落やインフラ点検など、用途ごとで最適化するためにAI性能を評価するには?https://built.itmedia.co.jp/bt/articles/2207/11/news024.html
(9)西尾 真由子,栗栖 雄一:橋梁点検部材損傷度判定CNNの可視化による判断根拠の理解と活用,AI・データサイエンス論文集,2020年1巻J1号p.92-99.https://doi.org/10.11532/jsceiii.1.J1_92
(10)杉崎 光一,阿部 雅人,全 邦釘:大規模言語モデルの専門領域への適用に関する検討,AI・データサイエンス論文集,2023年4巻3号p.474-481.https://doi.org/10.11532/jsceiii.4.3_474
(11)Attention Is All You Need.https://doi.org/10.48550/arXiv.1706.03762
(12)泉 翔太,堀 太成,山根 達郎,全 邦釘,藤森 祥文,森 脇亮:Deep Learningを用いたマイクロブログ投稿文の災害情報分類,AI・データサイエンス論文集,2020年1巻J1号
p.398-405.https://doi.org/10.11532/jsceiii.1.J1_398
(13)菅田 大輔,箱石 健太,一言 正之:土木・建設分野における大規模言語モデルの利活用に向けた検証と考察,AI・データサイエンス論文集,2023年4巻3号p.670-676.https://doi.org/10.11532/jsceiii.4.3_670
(14)櫻井 慶悟,前田 圭介,藤後 廉,小川 貴弘,長谷山 美紀:地下鉄トンネル点検時の一人称視点映像を用いたVision Transformerに基づく変状検出,AI・データサイエンス論文集,2022年3巻J2号p.470-478.https://doi.org/10.11532/jsceiii.3.J2_470
(15)Zhengyuan Yang,Linjie Li,Kevin Lin,Jianfeng Wang,Chung-Ching Lin,Zicheng Liu,Lijuan Wang:The Dawnof LMMs:Preliminary Explorations with GPT-4V(ision).https://doi.org/10.48550/arXiv.2309.17421
(16)青島 亘佐,宮内 芳維:大規模言語モデルの活用による橋梁点検調書作成の省力化に関する検討,AI・データサイエンス論文集,2023年4巻3号p.274-284.https://doi.org/10.11532/jsceiii.4.3_274
(17)稲富 翔伍,山根 達郎,金崎 裕之,全 邦釘:大規模言語モデルと画像セグメンテーションによる専門知識融合型土砂災害危険性判断手法,AI・データサイエンス論文集,2023年4巻3号p.507-514.https://doi.org/10.11532/jsceiii.4.3_507
(18)渡邉 優宇人,小川 直輝,前田 圭介,小川 貴弘,長谷山 美紀:Visual language modelを用いた変状画像に対する所見の自動生成̶類似画像検索によるFew-shot learningの導入̶,AI・データサイエンス論文集,2023年4巻3号p.223-232.https://doi.org/10.11532/jsceiii.4.3_223
【出典】
建設ITガイド 2024
特集1 建設DX、BIM/CIM

最終更新日:2024-07-26
最近の記事
- 関東地方整備局におけるBIM/CIMの取り組み―令和7年度は、関東インフラDXをさらに加速させます!—
- BIM/CIM積算によるデータ連携の取り組みの動向―わが国産学官チームが国際賞openBIM Awardsで日本初の部門最優秀賞賞!—
- 国土交通省におけるBIM/CIMの取り組みについて―BIM/CIMによる設計から施工へのデータ連携の推進 —
- 自治体におけるBIM活用事例|八幡市役所-BIMFMによる庁舎管理の省力化-
- 実技試験の開始で本格始動した「BIM利用技術者試験」制度
- 「建築仕様書の研究」から「BIM時代の建築仕様書」へ
- 大学のBIMセンターと産官学連携からみた台湾のBIM技術者育成
- 地方ゼネコンによるBIM活用の取り組みと展望-BIM連携の活用でパートナーシップの強化を目指す-
- 鉄筋工事におけるBIMを適用したワークフロー
- 大阪・関西万博工事のBIM活用-建設事業の情報基盤としてのBIMの成熟とその後の「あるべき姿」を目指して-
過去記事
-
2013
- 11月 (1)